java.util.Random 클래스
난수를 얻는 방법을 생각하면 Math.random()이 떠오를 것이다. 이 외에도 Random클래스를 사용하면 난수를 얻을 수 있다. 사실 Math.random()은 내부적으로 Random클래스의 인스턴스를 생성해서 사용하는 것이므로 둘 중에서 편한 것을 사용하면 된다. 아래의 두 문장은 동등하다.
double ranNum = Math.random();
double ranNum = new Random().nextDouble(); //위의 문장과 동일예를 들어 1~6사이의 정수를 난수로 얻고자 할 때는 다음과 같다.
int num = (int)(Math.random() *6) +1;
int num = new Random().nextInt(6) + 1; //nextInt(6)은 0~6사이의 정수를 반환Math.random()과 Random의 가장 큰 차이점이라면, 종자값(seed)을 설정할 수 있다는 것이다. 종자값이 같은 Random인스턴스들은 항상 같은 난수를 같은 순서대로 반환한다.
종자값은 난수를 만드는 공식에 사용되는 값으로 같은 공식에 같은 값을 넣으면 같은 결과를 얻는 것 처럼 같은 종자값을 넣으면 같은 난수를 얻게 된다.
Random클래스의 생성자와 메서드
생성자 Random()은 아래와 같이 종자값을 System.currentTimeMillis()로 하기 때문에 실행할 때마다 얻는 난수가 달라진다.
- System.currentTimeMillis()는 현재 시간을 천분의 1초단위로 변환해서 반환한다.
public Random(){
this.(System.currentTimeMillis()); //Random(long seed)를 호출한다.
}다음 표는 Random클래스의 메서드 목록인데, 별로 특별한 것은 없다. 각 메서드가 반환하는 값의 범위와 nextBytes()는 BigInteger(int signum, byte[] magnitude)와 함께 사용하면 int의 범위인 -2^31 ~ 2^31-1 보다 넓은 범위의 난수를 얻을 수 있다는 정도만 확인하자.
| 메서드 | 설명 |
| Random() | System.현재시간을 종자값(seed)으로 이용하는 Random인스턴스를 생성한다. |
| Random(long seed) | 매개변수 seed를 종자값으로 하는 Random인스턴스를 생성한다. |
| boolean nextBoolean() | boolean타입의 난수를 반환한다. |
| void nextBytes(byte[] bytes) | bytes배열에 byte타입의 난수를 채워서 반환한다. |
| double nextDouble() | double 타입의 난수를 반환한다.(0.0≤x<1.0) |
| float nextFloat() | float타입의 난수를 반환한다.(0.0≤x<1.0) |
| double nextGaussian() | 평균은 0.0이고 표준편차는 1.0인 가우시안(Gaussian)분포에 따른 double형의 난수를 반환한다. |
| int nextInt() | int타입의 난수를 반환한다.(int의 범위) |
| int nextInt(int n) | 0~n의 범위에 있는 int값을 반환한다.(n은 범위에 포함되지 않음) |
| long nextLong() | long타입의 난수를 반환한다.(long의 범위) |
| void setSeed(long seed) | 종자값을 주어진 값(seed)로 변경한다. |
import java.util.Random;
public class RandomEx1 {
public static void main(String[] args) {
Random rand = new Random(1);
Random rand2 = new Random(1);
System.out.println("= rand =");
for(int i=0; i<5; i++)
System.out.println(i+":"+rand.nextInt());
System.out.println();
System.out.println("= rand2 =");
for(int i=0; i< 5; i++)
System.out.println(i +":"+rand2.nextInt());
}
}
==================
= rand =
0:-1155869325
1:431529176
2:1761283695
3:1749940626
4:892128508
= rand2 =
0:-1155869325
1:431529176
2:1761283695
3:1749940626
4:892128508Random인스턴스 rand와 rand2가 같은 종자값(seed)을 사용하기 때문에 같은 값들을 같은 순서로 얻는 것을 확인할 수 있다. 우리의 컴퓨터에서 위와 같은 실행결과를 얻을 수 있을 것이다. 같은 종자값을 갖는 Random인스턴스는 시스템이나 실행시간 등에 관계없이 항상 같은 값을 같은 순서로 반환할 것을 보장한다.
import java.awt.PrintGraphics;
import java.util.Random;
public class RandomEx2 {
public static void main(String[] args) {
Random rand = new Random();
int[] number = new int[100];
int[] counter = new int[10];
for(int i =0; i<number.length; i++){
// System.out.print(number[i]=(int)(Math.random()*10));
// 0<= x <10 범위의 정수 x를 반환한다.
System.out.print(number[i]=rand.nextInt(10));
}
System.out.println();
for(int i=0; i<number.length;i++)
counter[number[i]]++;
for(int i =0; i< counter.length;i++)
System.out.println(i+"의 개수 :"+printGraph('#',counter[i])+" "+counter[i]);
}
public static String printGraph(char ch, int value){
char [] bar = new char[value];
for(int i=0; i<bar.length; i++)
bar[i] = ch;
return new String(bar);
}
}
====================
92624935720350584619135925829698523462895370382514847
88131803093849303178812470635870042551249475567
0의 개수 :######### 9
1의 개수 :######## 8
2의 개수 :########### 11
3의 개수 :############ 12
4의 개수 :########## 10
5의 개수 :############# 13
6의 개수 :###### 6
7의 개수 :######## 8
8의 개수 :############# 13
9의 개수 :########## 100~9 사이의 난수를 100개 발생시키고 각 숫자의 빈도수를 센 다음 그래프를 그리는 예제이다. nextInt(int n)는 0부터 n사이의 정수를 반환한다. 단, n은 범위에 포함되지 않는것에 주의하자.
import java.util.Arrays;
public class RandomEx3 {
public static void main(String[] args) {
for(int i=0; i< 10; i++)
System.out.print(getRand(5,10)+",");
System.out.println();
int[] result = fillRand(new int[10], new int[]{2,3,7,5});
System.out.println(Arrays.toString(result));
}
public static int[] fillRand(int[] arr, int from, int to){
for(int i =0 ; i< arr.length; i++)
arr[i] = getRand(from,to);
return arr;
}
public static int[] fillRand(int[] arr,int[] data){
for(int i =0 ; i< arr.length; i++)
arr[i] = data[getRand(0,data.length-1)];
return arr;
}
public static int getRand(int from, int to){
return (int)(Math.random()* (Math.abs(to-from)+1)) + Math.min(from,to);
}
}
============================
6,6,5,9,7,10,5,6,9,6,
[2, 7, 3, 3, 5, 5, 2, 3, 7, 5]Math.random()을 이용해서 실제 프로그래밍에 유용할만한 메서드를 만들어 보았다. 자 주 사용되는 코드를 메서드로 만들어 놓으면 여러모로 도움이 되므로 잘 정리해 두자.
int[] fillRand(int[] arr, int from, int to)
: 배열 arr을 from과 to범위의 값들로 채워서 반환한다.
int [] fillRand(int[] arr, int[] data)
:배열 arr을 배열 data에 있는 값들로 채워서 반환한다.
int getRand(int from, int to)(
:from과 to 범위의 정수(int)값을 반환한다. from과 to 모두 범위에 포함된다.
import java.util.*;
public class RandomEx4 {
final static int RECORD_NUM = 10; //생성할 레코드의 수를 정한다.
final static String TABLE_NAME = "TEST_TABLE";
final static String[] CODE1 = {"010","011","017","018","019"};
final static String[] CODE2 = {"남자", "여자"};
final static String[] CODE3 = {"10대","20대","30대","40대","50대"};
public static void main(String[] args) {
for(int i=0; i<RECORD_NUM;i++){
System.out.println(" INSERT INTO "+TABLE_NAME+" VALUES ("
+" '"+getRandArr(CODE1)+ "'"
+", '"+getRandArr(CODE2)+"'"
+", '"+getRandArr(CODE3)+"'"
+", "+getRand(100,200) //100~200사이의 값을 얻는다.
+");");
}
}
public static String getRandArr(String[] arr){
return arr[getRand(arr.length-1)]; //배열에 저장된 값 중 하나를 반환한다.
}
public static int getRand(int n) {
return getRand(0,n);
}
public static int getRand(int from, int to){
return (int)(Math.random()* (Math.abs(to-from)+1))+Math.min(from,to);
}
}
=============================
INSERT INTO TEST_TABLE VALUES ( '011', '여자', '30대', 181);
INSERT INTO TEST_TABLE VALUES ( '011', '남자', '10대', 177);
INSERT INTO TEST_TABLE VALUES ( '019', '여자', '40대', 147);
INSERT INTO TEST_TABLE VALUES ( '010', '남자', '30대', 173);
INSERT INTO TEST_TABLE VALUES ( '010', '남자', '40대', 155);
INSERT INTO TEST_TABLE VALUES ( '018', '남자', '20대', 127);
INSERT INTO TEST_TABLE VALUES ( '017', '남자', '10대', 169);
INSERT INTO TEST_TABLE VALUES ( '011', '여자', '20대', 181);
INSERT INTO TEST_TABLE VALUES ( '011', '남자', '10대', 185);
INSERT INTO TEST_TABLE VALUES ( '018', '남자', '40대', 187);데이터베이스에 넣을 테스트 데이터를 만드는 예제이다. 지금까지는 연속적인 범위 내에서 값을 얻어왔지만, 때로는 이 예제와 같이 불연속적인 범위에 있는 값을 임의로 얻어와야 하는 경우도 있다.
이런 경우 불연속적인 값을 배열에 저장한 후, 배열의 index를 임의로 얻어 배열에 저장된 값을 읽어오도록하면 된다. 아직 데이터베이스를 배우지 않은 살마도 있겠지만, 앞으로 데이터베이스를 배우게 되면, 이 예제가 다량의 테스트 데이터를 생성하는데 유용하게 쓰일 것이다.
정규식(Regular Expression) -java.util.regex 패키지
정규식이란 텍스트 데이터 중에서 원하는 조건(패턴, pattern)과 일치하는 문자여릉ㄹ 찾아내기 위해 사용하는것으로 미리 정의된 기호와 문자를 이용해서 작성한 문자열을 말한다. 원래 Unix에서 사용하던 것이고 Perl의 강력한 기능이었는데 요즘은 Java를 비롯해 다양한 언어에서 지원하고 있다.
정규식을 이용하면 많은 양의 텍스트 파일 중에서 원하는 데이터를 손쉽게 뽑아낼 수도 있고 입력된 데이터가 형식에 맞는지 체크할 수도 있다. 예를 들면 html문서에서 전화번호나 이메일 주소만을 따로 추출한다거나, 입력한 비밀번호가 숫자와 영문자의 조합으로 되어 있는지 확인할 수 있다.
Java API문서에서 java.util.regex.Pattern을 찾아보면 정규식에 사용되는 기호와 작성방법이 모두 설명되어 있지만, 처음부터 이 내용만으로 정규식을 어떻게 작성해야할지 이해하기가 쉽지는 않을 것이다. 정규식을 자세히 설명하면 광범위 하기 떄문에 깊이 있게 학습하는 것보다는 자주 쓰이는 정규식의 작성 예를 보고 응용할 수 있을 정도까지만 학습하고 넘어가는 것이 좋다.
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularEx1 {
public static void main(String[] args) {
String[] data ={"bat", "baby", "bonux", "cA", "ca","co", "c.","c0","car","combat",
"count", "date", "disc"};
Pattern p = Pattern.compile("c[a-z]*"); //c로 시작하는 소문자 영단어
for(int i=0; i<data.length; i++){
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i]+",");
}
}
}
======================
ca,co,car,combat,count,data라는 문자열 배열에 담긴 문자열 중에서 지정한 정규식과 일치하는 문자열을 출력하는 예제이다. Pattern은 정규식을 정의하는데 사용되고 Matcher은 정규식(패턴)을 데이터와 비교하는 역할을 한다. 정규식을 정의하고 데이터를 비교하는 과정을 단계별로 설명하면 다음과 같다.
- 정규식을 매개변수로 Pattern클래스의 static메서드인 Pattern compile(String regex)을 호출하여 Pattern인스턴스를 얻는다.
- Pattern p = Pattern.compile("c[a-z]*");
- 정규식으로 비교할 대상을 매개변수로 Pattern클래스의 Matcher matcher(CharSequence input)를 호출해서 Matcher 인스턴스를 얻는다.
- Matcher m = p.matcher(data[i]);
- Matcher인스턴스에 boolean matches()를 호출해서 정규식에 부합하는지 확인한다.
- if(m.matches())
- CherSequence는 인터페이스로, 이를 구현한 클래스는 CharBuffer, String, StringBuffer가 있다.
import java.util.regex.*; //Pattern과 Matcher가 속한 패키지
public class RegularEx2 {
public static void main(String[] args) {
String[] data ={"bat", "baby", "bonux", "cA", "ca","co", "c.","c0","car","combat",
"count", "date", "disc"};
String[] pattern={".*","c[a-z]*","c[a-z]","c[a-zA-Z]",
"c[a-zA-Z0-9]","c.","c.*","c\\.","c\\w","c\\d",
"c.*t", "[b|c].*", ".*a.*",".*a.+","[b|c].{2}"};
for(int x=0; x< pattern.length; x++){
Pattern p = Pattern.compile(pattern[x]);
System.out.print("Pattern : "+pattern[x]+" 결과:");
for(int i=0; i<data.length;i++){
Matcher m = p.matcher(data[i]);
if(m.matches())
System.out.print(data[i]+",");
}
System.out.println();
}
}
}
======================================
Pattern : .* 결과:bat,baby,bonux,cA,ca,co,c.,c0,car,combat,count,date,disc,
Pattern : c[a-z]* 결과:ca,co,car,combat,count,
Pattern : c[a-z] 결과:ca,co,
Pattern : c[a-zA-Z] 결과:cA,ca,co,
Pattern : c[a-zA-Z0-9] 결과:cA,ca,co,c0,
Pattern : c. 결과:cA,ca,co,c.,c0,
Pattern : c.* 결과:cA,ca,co,c.,c0,car,combat,count,
Pattern : c\. 결과:c.,
Pattern : c\w 결과:cA,ca,co,c0,
Pattern : c\d 결과:c0,
Pattern : c.*t 결과:combat,count,
Pattern : [b|c].* 결과:bat,baby,bonux,cA,ca,co,c.,c0,car,combat,count,
Pattern : .*a.* 결과:bat,baby,ca,car,combat,date,
Pattern : .*a.+ 결과:bat,baby,car,combat,date,
Pattern : [b|c].{2} 결과:bat,car,자주 쓰일 만한 패턴들을 만들어서 테스트하고 그 결과를 정리하였다. 이 패턴들을 이해하고 나면 정규식에 사용되는 다른 기호를 사용하는 방법도 이해하기 쉬어질 것이다.
| 정규식 패턴 | 설명 | 결과 |
| c[a-z]* | c로 시작하는 영단어 | ca,co,car,combat,count, |
| c[a-z] | c로 시작하는 두 자리 영단어 | ca,co, |
| c[a-zA-Z] | c로 시작하는 두 자리 영단어(a~z 또는 A~Z, 즉 대소문자 구분안함)_ | cA,ca,co, |
| c[a-zA-Z0-9] | c로 시작하고 숫자와 영어로 조합된 두글자 | cA,ca,co,c0, |
| .* | 모든 문자열 | bat,baby,bonux,cA,ca,co,c.,c0,car,combat,count,date,disc, |
| c. | c로 시작하는 두 자리 문자열 | cA,ca,co,c.,c0, |
| c.* | c로 시작하는 모든 문자열(기호 포함) | cA,ca,co,c.,c0,car,combat,count, |
| c\. | C와 일치하는 문자열 '.'은 패턴 작성에 사용되는 문자이므로 excape문자인 '\'을 사용해야 한다. | c., |
| c\d c[0-9] | c와 숫자로 구성된 두 자리 문자열 | c0, |
| c.*t | c로 시작하고 t로 끝나는 모든 문자열 | combat,count, |
| [b|c].* [bc].* [b-c].* | b또는 c로 시작하는 문자열 | bat,baby,bonux,cA,ca,co,c.,c0,car,combat,count, |
| [^b|c].* [^bc].* [^b-c].* | b또는 c로 시작하지 않는 문자열 | date,disc, |
| .*a.* | a를 포함하는 문자열 *: 0 또는 그 이상의 문자 | bat,baby,ca,car,combat,date, |
| .*a.+ | a를 포함하는 모든 문자열 + : 1Ehsms rm dltkddml answk, '+'는 '*'과는 달리 반드시 하나 이상의 문자가 있어야 하므로 a로 끝나는 단어는 포함되지 않았다. | bat,baby,car,combat,date, |
| [b|c].{2} | b또는 c로 시작하는 세자리 문자열 (b 또는 c 다음에 두 자리이므로 모두 세자리) | bat,car, |
import java.util.regex.*;
public class RegularEx3 {
public static void main(String[] args) {
String source = "HP:011-1111-1111, HOME:02-999-9999";
String pattern ="(0\\d{1,2})-(\\d{3,4})-(\\d{4})";
Pattern p = Pattern.compile(pattern);
Matcher m = p.matcher(source);
int i = 0;
while(m.find()){
System.out.println(++i+": "+m.group()+" -> "+m.group(1)+", "+m.group(2)+", "+m.group(3));
}
}
}
=====================
1: 011-1111-1111 -> 011, 1111, 1111
2: 02-999-9999 -> 02, 999, 9999정규식의 일부를 괄호로 나누어 묶어서 그룹화(grouping)할 수 있다. 그룹화된 부분은 하나의 단위로 묶이는 셈이 되어서 한 번 또는 그 이상의 반복을 의미하는 '+'나 '*'가 뒤에 오면 그룹화 된 부분이 적용대상이 된다. 그리고 그룹화된 부분은 group9int i)를 이용해서 나누어 얻을 수 있다.
위의 예제에서 '(0\\d{1,2})-(\\d{3,4})-(\\d{4})'은 괄호를 이용해서 정규식을 세 부분으로 나누었는데 예제와 결과에서 알 수 있듯이 매칭되는 문자열에서 첫번째 그룹은 group(1)로 두번째 그룹은 group(2)와 같이 호출함으로써 얻을 수 있다. group()또는 group(0)은 그룹으로 매칭된 문자열을 전체를 나누어지지 않은 채로 반환한다.
- group(int i)를 호출할 때 i가 실제 그룹의 수 보다 많으면 java.lang.indexOutOfBoundingException이 발생한다.
(0\\d{1,2}) : 0으로 시작하는 최소 2자리 최대 3자리 숫자(0포함)
(\\d{3,4}) : 최소 3자리 최대 4자리의 숫자
(\\d{4}) : 4자리의 숫자
find()는 주어진 소스 내에서 패턴과 일치하는 부분을 찾아내면 true를 반환하고 찾지 못하면 false를 반환한다. find()를 호출해서 패턴과 일치하는 부분을 찾아낸다음, 다시 find()를 호출하면 이전에 발견한 패턴과 일치하는 부분의 다음부터 다시 패턴매칭을 시작한다.
Matcher m = p.matcher(source):
while(m.find()) { //find()는 일치하는 패턴이 없으면 false를 반환한다.
System.out.println(m.group());
}import java.util.regex.*;
public class RegularEx4 {
public static void main(String[] args) {
String source = "A broken hand works, but not a broken heart.";
String pattern = "broken";
StringBuffer sb = new StringBuffer();
Pattern p = Pattern.compile(pattern);
Matcher m = p.matcher(source);
System.out.println("source:"+source);
int i = 0;
while(m.find()){
System.out.println(++i+"번째 매칭:"+m.start()+"~"+m.end());
//broken을 drunken으로 치환하여 sb에 저장한다.
m.appendReplacement(sb, "drunken");
}
m.appendTail(sb);
System.out.println("Replacement count : "+i);
System.out.println("result : "+sb.toString());
}
}
========================
source:A broken hand works, but not a broken heart.
1번째 매칭:2~8
2번째 매칭:31~37
Replacement count : 2
result : A drunken hand works, but not a drunken heart.Matcher의 find(0로 정규식과 일치하는 부분을 찾으면 , 그 위치를 start()와 end()로 알 아 낼수 있고 appendReplacement(StringBuffer sb, String replacement)를 이용해서 원하는 문자열 (replacement)로 치환할 수 있다. 치환된 결과인 StringBuffer인 sb에 저장되는데, sb에 저장되는 내용을 단계별로 살펴보면 이해하기 쉬울 것이다.
- 명령어 source에서 "broken"을 m.find(0로 찾은 후 처음으로 m.appendReplacement(sb,"drunken"); 가 호출되면 source의 시작부터 "broken"을 찾은 위치까지의 내용에 "drunken"을 더해서 저장한다.
- -sb에 저장된 내용 :"A drunken"
- m.find()는 첫 번째로 발견된 위치의 끝에서부터 다시 검색을 시작하여 두 번째 "broken"을 찾게 된다. 다시 m.appendReplacement(sb, "drunken"); 가 호출
- -sb에 저장된 내용 : "A drunken hand works, but not a drunken"
- m.appendTail(sb); 이 호출되면 마지막으로 치환된 이후의 부분을 sb에 덧붙인다.
- -sb에 저장된 내용 : "A drunken hand works, but not a drunken heart."
java.util.Scanner 클래스
Scanner는 화면, 파일, 문자열과 같은 입력소스로부터 문자데이터를 읽어오는데 도움을 줄 목적으로 JDK1.5부터 추가되었다. Scanner에는 다음과 같은 생성자를 지원하기 때문에 다양한 입력소스로부터 데이터를 읽을 수 있다.
Scanner (String source)
Scanner (File source)
Scanner (InputStream source)
Scanner(Readable source)
Scanner (ReadableByteChannel source)
Scanner (Path source) //JDK 1.7 부터 추가또한 Scanner는 정규식 표현(Regular expression)을 이용한 라인단위의 검색을 지원하며 구분자(delimiter)에도 정규식 표현을 사용할 수 있어서 복잡한 형태의 구분자도 처리가 가능하다.
Scanner useDelimiter(Pattern pattern)
Scanner useDelimiter(String pattern)Scanner가 없던 JDK1.5이전에는 자바는 화면으로부터 입력받는 것이 왜 이렇게 불편하냐는 개발자들의 문의가 많았으나 Scanner덕분에 더이상 이런 문의는 받지 않게 되었다.
JDK1.6부터는 화면 입출력만 전문적으로 담당하는 java.io.Console이 새로 추가되었다.
Console은 이클립스와 같은 IDE에서 잘 동작하지 않는다. 이 두 클래스는 사용법이나 성능측면에서 거의 같기 떄문에 어떤것을 사용해도 상관없다.
//JDK1.5이전
BufferedReader br = new BuffredReader(new InputStreamReader(System.in));
String imput = br.readLine();
//JDK 1.5 이후(java.uti.Scanner)
Scanner s = new Scanner(System.in);
String input = s.nextLine();
//JDK 1.6 이후 (java.io.Console) - 이클립스에서 동작하지 않는다.
Console console = System.console();
String input = console.readLine();입력받을 값이 숫자라면 nextLine()대신 nextInt()또는 nextLong()과 같은 메서드를 사용할 수 있다. Scanner에서는 이와 같은 메서드를 제공함으로써 입력받은 문자를 다시 변환하는 수고를 덜어준다.
boolean nextBoolean();
byte nextByte();
short nextShort();
int nextInt();
long nextLong();
double nextDouble();
float nextFloat();
String nextLine();- 실제 입력된 데이터의 형식에 맞는 메서드를 사용하지 않으면, inputMismatchException이 발생한다.
import java.util.Scanner;
public class ScannerEx1 {
public static void main(String[] args) {
Scanner s = new Scanner(System.in);
String[] argArr = null;
while(true){
String prompt = ">>";
System.out.print(prompt);
//화면으로부터 라인단위로 입력받는다.
String input = s.nextLine();
input = input.trim(); //입력받은 값에서 불필요한 앞뒤 공백을 제거한다.
argArr = input.split(" +"); //입력받은 내용을 공백을 구분자로 자른다.
String command = argArr[0].trim();
if("".equals(command)) continue;
//명령어를 소문자로 바꾼다.
command = command.toLowerCase();
//q또는 Q를 입력하면 실행 종료된다.
if(command.equals("q")){
System.exit(0);
}else{
for(int i =0; i< argArr.length; i++)
System.out.println(argArr[i]);
}
}
}
}
====================
>>hello
hello
>>hello 123
hello
123
>>hello 123 456
hello
123
456
>>q화면으로부터 라인단위로 입력 받아서 입력받은 내용의 공백을 구분자로 나눠서 출력하는 예제이다. 입력받은 라인의 단어는 공백이 여러 개 일 수 있으므로 정규식을 " +"로 하였다. 이 정규식의 의미는 하나 이상의 공백을 의미한다.
argArr = input.split(" +"); //입력받은 내용의 공백을 구분자로 자른다.이 예제를 발전시켜서 도스같은 콘솔 어플리케이션을 작성해보면 좋은 공부가 될것이다.
import java.io.File;
import java.io.FileNotFoundException;
import java.util.Scanner;
public class ScannerEx2 {
public static void main(String[] args) throws Exception {
Scanner sc = new Scanner(new File("data2.txt"));
int sum = 0;
int cnt = 0;
while(sc.hasNextInt()){ //입력받은 값이 정수일때 true
sum += sc.nextInt();
cnt++;
}
System.out.println("sum="+sum);
System.out.println("average="+(double)sum/cnt);
}
}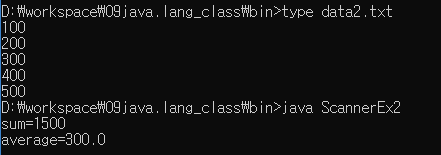
data2.txt파일로부터 데이터를 읽어서 합과 평균을 계산하는 예제이다. 여기서는 data2.txt파일이 예제소스파일인 ScannerEx2.java와 같은 디렉토리에 있어서 경로없이 파일명만 지정해주었지만, 소스파일과 다른 디렉토리에 위치한 파일을 읽기 위해서는 파일명에 경로도 함께 지정해주어야 한다.
import java.io.File;
import java.util.Scanner;
public class ScannerEx3 {
public static void main(String[] args) throws Exception {
Scanner sc = new Scanner(new File("data3.txt"));
int cnt = 0;
int totalSum = 0;
while(sc.hasNextInt()){
String line = sc.nextLine();
Scanner sc2 = new Scanner(line).useDelimiter(",");
int sum = 0;
while(sc2.hasNextInt()){
sum += sc2.nextInt();
}
System.out.println(line+ ", sum="+sum);
totalSum += sum;
cnt++;
}
System.out.println("Line: "+cnt+", Total: "+totalSum);
}
}
이전 예제와 같이 파일로부터 데이터를 읽어서 계산하는 예제인데 이전과는 달리 ','를 구부낮로 한 라인에 여러 데이터가 저장되어 있다. 이럴 때는 파일의 내용을 먼저 라인별로 읽은 다음에 다시 ','를 구분자로 하는 Scanner를 이용해서 각각의 데이터를 읽어야 한다.
java.util.StringTokenizer 클래스
StringTokenizer는 긴 문자열을 지정된 구분자(delimiter)를 기준으로 토큰(token)이라는 여러 개의 문자열로 잘라내는데 사용된다. 예를 들어 "100,200,300,400"이라는 문자열이 있을 떄 ','를 구분자로 잘라내면 "100","200","300","400"이라는 4개의 문자열(토큰)을 얻을 수 있다.
StringTokenizer를 이용하는 방법 이외에도 아래와 같이 String의 split(String regex)이나 Scanner의 useDelimiter(String pattern)를 사용할 수도 있지만,
String[] result = "100,200,300,400".split(",");
Scanner sc2 =new Scanner("100,200,300,400").useDelimiter(",");이 두가지 방법은 정규식 표현(Regular expression)을 사용해야하므로 정규식 표현에 익숙하지 않은 경우 StringTokenizer를 사용하는 것이 간단하면서도 명확한 결과를 얻을 수 있을 것이다.
그러나 StringTokenizer는 구분자로 단 하나의 문자밖에 사용하지 못하기 때문에 보다 복잡한 형태의 구분자로 문자열을 나누어야 할때는 어쩔수 없이 정규식을 사용하는 메서드를 사용해야 할 것이다.
StringTokenizer의 생성자와 메서드
StirngTokenizer의 주로 사용되는 생성자와 메서드는 다음과 같다.
| 생성자/메서드 | 설명 |
| StringTokenizer(String str, String delim) | 문자열(str)을 지정된 구분자(delim)로 나누는 StringTokenizer를 생성한다. (구분자는 토큰으로 관리되지 않음) |
| StringTokenizer(String str, String delim, boolean returnDelims) | 문자열(str)을 지정된 구분자(delim)로 나누는 StringTokenizer를 생성한다. returnDelims의 값을 true로 하면 구분자도 토큰으로 간주된다. |
| int countTokens() | 전체 토큰의 수를 반환한다. |
| boolean hasMoreToken() | 토큰이 남았는지 알려준다. |
| String nextToken() | 다음 토큰을 반환한다. |
import java.util.StringTokenizer;
public class StringTokenizerEx1 {
public static void main(String[] args) {
String source = "100,200,300,400";
StringTokenizer st = new StringTokenizer(source, ",");
while(st.hasMoreTokens()){
System.out.println(st.nextToken());
}
}
}
==================
100
200
300
400','을 구분자로 하는 StringTokenizer를 생성해서 문자열(source)을 나누어 출력하는 예제이다. 간단한 예제이므로 자세한 설명을 생략한다.
import java.util.StringTokenizer;
public class StringTokenizerEx2 {
public static void main(String[] args) {
String expression = "x=100*(200+300)/2";
StringTokenizer st = new StringTokenizer(expression,"+-*/=()",true);
while(st.hasMoreTokens()){
System.out.println(st.nextToken());
}
}
}
==================
x
=
100
*
(
200
+
300
)
/
2생성자 StringTokenizer(String str, String delim, boolean returnDelims)를 사용해서 구분자도 토큰으로 간주되도록 하였다.
StringTokenizer st =new StringTokenizer(expression, "+-*/=()", true);그리고 구분자로 여러 문자들을 지정한 것을 눈여겨보자. 앞서 얘기한 바와 같이 StringTokenizer는 단 한 문자의 구분자만 사용할 수 있기 때문에, "+-*/=()"전체가 하나의 구분자가 아니라 각각의 문자가 모두 구분자라는 것에 주의해야 한다.
- 만일 구분자가 두 문자 이상이라면, Scanner나 String클래스의 split메서드를 사용해야 한다.
import java.util.StringTokenizer;
public class StringTokenizerEx3 {
public static void main(String[] args) {
String source = "1,김천재,100,100,100|2,박수재,95,80,90|3,이자바,80,90,90";
StringTokenizer st = new StringTokenizer(source, "|");
while(st.hasMoreTokens()){
String token = st.nextToken();
StringTokenizer st2 = new StringTokenizer(token, ",");
while(st2.hasMoreTokens())
System.out.println(st2.nextToken());
System.out.println("------");
}
}
}
===================
1
김천재
100
100
100
------
2
박수재
95
80
90
------
3
이자바
80
90
90
------문자열에 포함된 데이터가 두 가지 종류의 구분자로 나뉘어져 있을 때 두 개의 StringTokenizer와 이중 반복문을 사용해서 처리하는 방법을 보여주는 예제이다. 한 학생의 정보를 구분하기 위해 "|"를 사용하였고, 학생의 이름과 점수 등을 구분하기 위해 ","를 사용하였다.
import java.util.StringTokenizer;
public class StringTokenizerEx4 {
public static void main(String[] args) {
String input="삼십만삼천백십오";
System.out.println(input);
System.out.println(hangulToNum(input));
}
public static long hangulToNum(String input){ //한글을 숫자로 바꾸는 메서드
long result = 0; //최종 변환 결과를 저장하기 위한 변수
long tmpResult = 0; //십백천 단위의 값을 저장하기 위한 임시변수
long num = 0;
//삼 십 만 삼 천 백 십 오
final String NUMBER = "영일이삼사오육칠팔구";
final String UNIT = "십백천만억조";
final long[] UNIT_NUM = {10,100,1000,10000,(long)1e8,(long)1e12};
StringTokenizer st = new StringTokenizer(input,UNIT,true);
while(st.hasMoreTokens()){
String token = st.nextToken();
int check = NUMBER.indexOf(token); //숫자인지, 단위(UNIT)인지 확인한다.
if(check == -1){ //단위인 경우
if("만억조".indexOf(token) == -1){
tmpResult += (num != 0 ? num : 1)* UNIT_NUM[UNIT.indexOf(token)];
}else{
tmpResult += num;
result += (tmpResult != 0 ? tmpResult :1)*UNIT_NUM[UNIT.indexOf(token)];
tmpResult = 0;
}
num = 0;
}else {//숫자인 경우
num = check;
}
}
return result + tmpResult+num;
}
}
==============================
삼십만삼천백십오
303115한글로 된 숫자를 아라비아 숫자로 변환하는 예제이다. 짧지만 조금 어려울 수도 있기 때문에 예제를 보기전에 어떻게 이 문제를 풀 것인가를 고민해 보면 이해하는데 많은 도움이 될 것이다.
먼저 tmpResult는 "만억조"와 같은 큰 단위가 나오기 전까지 "십백천"단위의 값을 저장하기 위한 임시공간이고, result는 실제 결과값을 저장하기 위한 공간임을 알아두자.
한글로 된 숫자를 구분자(단위)로 잘라서, 토큰이 숫자면 num에 저장하고 단위면 num에다 단위(UNIT_NUM 배열 중의 한 값)를 곱해서 tmpResult에 저장한다. 예를 들어 '"삼십"이면 3*10 = 30이되어 tmpReulst에 저장된다.
그리고 "만삼천"과 같이 숫자없이 바로 단위로 시작하는 경우에는 num의 값이 0이기 때문에 단위의 값을 곱해도 그 결과가 0이되므로 삼항 연산자를 이용해서 num의 값을 1로 바꾼 후 단위값을 곱하도록 하였다.
tmpResult += (num !=0 ? num : 1) * UNIT_NUM(UNIT.indexOf(token));그 다음에 "만억조"와 같이 큰 단위가 나오면 tempResult에 저장된 값에 큰 단위 값을 곱해서 result에 저장하고 tmpResult는 0으로 초기화 한다. 예를 들어 "삼십만"은 tmpResult에 저장되어있던 30에 10000을 곱해서 result에 저장하고, tmpResult는 0으로 초기화 한다.
tmpResult += num;
result += (tmpResult != 0 tmpResult : 1) *UNIT_NUM(UNIT.indexOf(token)];
tmpResult = 0;import java.util.*;
public class StringTokenizerEx5 {
public static void main(String[] args) {
String data = "100,,,200,300";
String[] result = data.split(",");
StringTokenizer st = new StringTokenizer(data, ",");
for(int i=0; i<result.length; i++)
System.out.print(result[i]+"|");
System.out.println("개수 :"+result.length);
int i=0;
for(;st.hasMoreTokens();i++)
System.out.print(st.nextToken()+"|");
System.out.println("개수 :"+i);
}
}
=================
100|||200|300|개수 :5
100|200|300|개수 :3구분자를 ','로 하는 문자열 데이터를 String클래스의 split()과 StringTokenizer로 잘라낸 결과를 비교하는 예제이다. 실행결과를 보면, split()은 빈 문자열도 토큰으로 인식하는 반면 StringTokenizer은 빈 문자열을 토큰으로 인식하지 않기 때문에 인힉하는 토큰의 개수가 서로 다른것을 알 수 있다.
이 외에도 성능의 차이가 있는데, split()은 데이터를 토큰으로 잘라낸 결과를 배열에 담아서 반환하기 때문에 데이터를 토큰으로 바로바로 잘라 반환하는 StringTokenizer보다 성능이 떨어질 수밖에 없다. 그러나 데이터의 양이 많은 경우가 아니라면 별 문제가 되지않으므로 크게 신경 쓸 부분은 아니다.
'Back-end' 카테고리의 다른 글
| 10 날짜와 시간 & 형식화(1) (0) | 2021.07.02 |
|---|---|
| java.lang패키지와 유용한 클래스(8) (0) | 2021.07.01 |
| java.lang패키지와 유용한 클래스(6) (0) | 2021.06.29 |
| java.lang패키지와 유용한 클래스(5) (0) | 2021.06.27 |
| java.lang패키지와 유용한 클래스(4) (0) | 2021.06.26 |
